Hello! My name is Alexander Mordvintsev, I'm a tinkerer, coder, researcher, and artist. I visualize things to understand how they work. My most known creation is DeepDream, a program I developed while exploring Deep Neural Networks. This curiosity about complex systems led me to study how living organisms self-organize, resulting in the Neural Cellular Automata model. Currently, I'm exploring the foundations of computation in technology and life, seeking to bridge the gap between artificial and biological systems.
Recent Projects
Tiny Tapeout Explorer

Interactive 3D circuit visualization and switch-level simulation for Tiny Tapeout silicon designs.
Growing Graphs

An exploration of emergent complexity through graph-rewriting automata. Watch simple rules evolve into intricate networks in real-time, powered by high-performance WebAssembly physics and smooth WebGL rendering.
Cellular Automata VGA Circuit

An ASIC design for generating VGA signals to display scrolling cellular automata patterns, with an accompanying web-based gate-level simulator.
SwissGL library
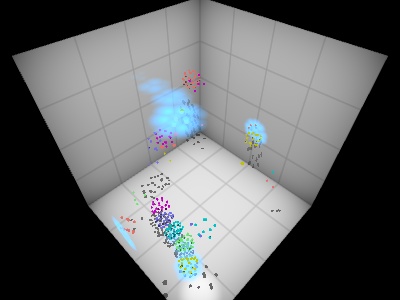
A prototype of a minimal yet expressive GPU programming library built on WebGL2.
Particle Lenia
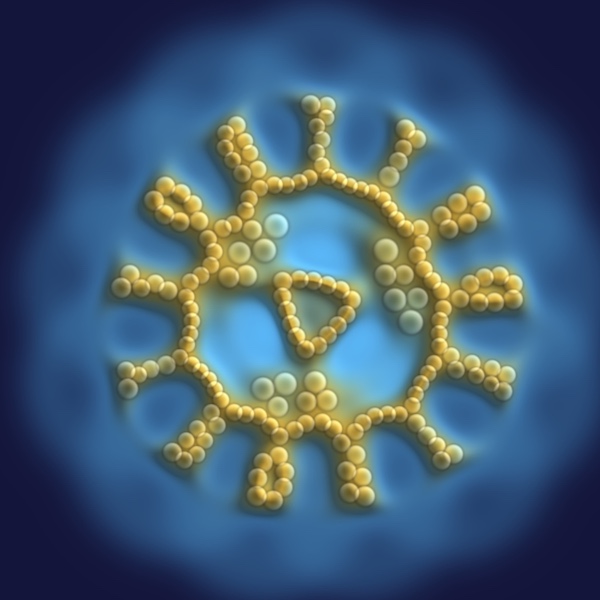
Particle Lenia is an artificial life system that produces complex dynamic patterns from simple rules of particle interaction. Learn how to implement it from scratch in the interactive JS tutorial.
Hexells

Hexells is an art project where digital cells learn to talk to their neighbors to create unique textures. Using Neural Cellular Automata, it shows how local interactions between cells can grow into beautiful, globaly coherent patterns.
Tutorials
Simple 3D visualization with JAX

I demonstrate how to implement simple 3D scene rendering using a raycasting algorithm in JAX. This approach enables creating visualizations with the same toolset used in ML experiments.
Differentiable Finite State Machines

Differentiable optimization can be used to learn FSMs for toy string processing tasks. Simple regularization and initialization techniques can steer continuous optimization towards discrete deterministic solutions.
Featured Press
More coming soon...